
Centre for Kurdish Studies
GAUTIER Gérard1
ggautier@club-internet.fr
Paper presented at ICEMCO 98
6th International Conference and Exhibition on Multilingual Computing
Cambridge, UK, April 1998
Building a Kurdish Language Corpus
An overview of the Technical Problems
- Note: As the original, this HTML version of the paper uses Kurdish Latin and Arabic-type characters as well as specific diacritic signs. HTML does not allow for their representation in a simple way, so they had to be realised graphically. They will integrate at best into the text flow if this paper is viewed with a browser whose proportional font has been set to Times or Times New Roman 13 or 14 size.
|
Abstract :
Keywords : Kurdish, multiscript, corpus, lexicography.
This paper proposes a first exploration of the problems to tackle to launch a cooperative project for the realisation of a Kurdish Language Corpus. After introducing the general principles and aims of the actual trend of corpora building, it turns to the specifics of Kurdish language situation, which is characterised by a profusion of dialects and writing systems (Arabic-Persian, Roman, and Cyrillic), and by the lack of a standardised digital representation.
This complexity makes paradoxally computers very useful, as they allow to present the data according to the needs of users familiar with different writing systems. It leads to define principles of action proper to a Kurdish corpus, and the author examines the different types of data concerned and puts forward a hierarchised model of layered data entities and processing functions from which the concrete organisation of the project could start.
1. Building corpora...
1.1 Introduction
This paper is part of a collective reflexion recently started about the building of a national corpus of Kurdish language. It will focus on the technical problems proper to Kurdish, giving the minimum contextual information to tackle this subject. On the other hand, as one part at least of the difficulties peculiar to Kurdish are probably also encountered when trying to gather and represent under digital form language data on any minority language divided into subdialects2 (and furthermore for languages using as Kurdish several writing systems), I hope my contribution will be of some use to researchers or speakers of other linguistic minorities as well.
1.2 The common field of corpora builders
There is a renewal of the interest of the research community for electronic corpora, defined as "collections of language data selected and organised according to explicit linguistic criterions to be used as language samples" (after [SINCLAIR, 1996]). The idea of corpus itself is not so new : the constitution of corpora started as early as in the sixties, a French example being the collection of 160 million words built by the Institut National de la Langue Française, which resulted into the FRANTEXT text base and the seventeen volumes of Trésor national de la langue française (National Treasury of French Language).
But what is new is the scope of the corpora (they are much bigger), their better accessibility [HABERT et al., 1997, p. 7], and the progressive normalisation of the techniques used to build, process, and make use of them. Specifically, the publication of the important standardising guidelines constituted by the Text Encoding Initiative open the perspective of a common field for all the researchers working on the realisation of corpora, whatever is their original academic field : those guidelines were themselves conceived by a vast community of authors.
1.3 What is in a corpus
To describe the contents of corpora, I will here use the word "text", as it is often under a textual form, that the contents of a corpus are usually put together. But it should not be forgotten that the "texts" found in a corpus are not just text in the traditional way. They may indeed be just originally written texts (literary, press and essay, technical), but for the sake of representativity (a concept itself much discussed among researchers), corpora will often also include traditional narration (myths...), written transcription of (recorded) discourses (and even the voice itself), and also other synthetising sources as dictionaries and (specialised) lexicons (The TEI provides a section for encoding terminological databases as well)...
1.4 Types of corpora and general principles of building
To keep this section the shortest, I will simultaneously introduce the general classification of corpora by opposite characteristics proposed by C. BALL [URL : BALL, 1997], and the preliminary choices proposed for the Kurdish corpus3. Then I will present the principles governing corpora constitution, while highlighting the difficulties of their application to the Kurdish case.
C. BALL distinguishes :
- Synchronic (gathering texts from inside a time window of typically some decades to bear testimony of the state of a language, as Cobuild dictionary does) versus diachronic (following the evolution of the language during the chosen period, which may be several centuries long, as in FRANTEXT, which goes from XVIth century up to now). For Kurdish, it is proposed to build a dominantly synchronic corpus with some older "founding texts".
- Monolingual versus multilingual. This opposition seems clear enough. The multilingual corpora may be parallel, (gathering different translations of the same texts or texts written in different languages about the same subject), or even aligned, corresponding position labels being inserted in the texts of each language, allowing to relate each segment of text (paragraphs, sentences) across the languages of the corpus. This allows translation or lexicography researches. In the case of Kurdish, it is proposed to align texts across the different Kurdish dialects, and with foreign language translations4 when they are available. This would become a criterion for the choice of Kurdish texts to include.
- Tagged or untagged corpus : inserting labels into text - as just been mentionned - is called tagging text. This practice is gaining currency more and more in corpus research field, for aims which depend on each project (such as part-of-speech tagging for allowing future NLP - Natural Language Processing - research). TEI proposes a set of tools adaptable to different texts and aims (Text Encoding Initiative, also Corpus Encoding Standard, 1997). However, untagged or lightly tagged corpora are not at all unuseful5, and given the state of Kurdish corpus disponibility, it is proposed to start with a simple structural, minimum, tagging : the divisions of a text in pages, chapters, paragraphs, stanzas, etc, plus "classical" bibliographical information (author, date of publication, publisher, type of text, commentary...) and the contextual informations already mentionned. Structural tagging would allow to prepare multilingual and Kurdish multidialectal aligned texts.
- Linguistic (as part-of-speech) or semantic tagging (of the type used by anthropologists [BERNARD, 1988, pp. 346 sq.]) will be considered as separate experiments on subsets of the corpus, made possible according to means.
1.5 General principles in corpora building
Obtaining corpus "texts" (in the meaning defined section 1.2) means submitting the data under its original form to a processing. There are general principles which must be followed if a work of scientific quality is to be done. The seemingly simplest case, the originally written, printed, piece of language (by opposition to a tape for instance), already shows the extant of difficulties to overcome.
The interest of digitalising such data is that it allows to submit the text to new types of processing and to extract new data from it, but this must not be done at the expanse of the lost of any of the original information. That can actually lead the researcher to add extra-textual information, as the original price of the publication (which may give hints to the researcher as to the intended readership) or the original area of the writer (which may give precious linguistic subdialectal information)... TEI in its headers provides for this contextual information6.
But the problems for Kurdish go beyond this one, and this paper tries to draw the attention of researchers and potential contributors to Kurdish corpus to the specific conceptual and technical difficulties of building a sound processing chain for Kurdish original printed texts. In fact, those difficulties lead to define special aims which translate into special functionalities.
2. ...and building a Kurdish corpus
2.1. The different Kurdish dialects, sub-dialects, and writing systems7
To understand why Kurdish brings specific technical problems to the corpus builder, it is necessary to enter into some linguistic aspects. To keep them to a minimum, I will mention each writing system together with the dialect(s) it covers, although there is only a de facto relationship between writing systems and dialects. The fact that there is here neither a linguistic nor a logical necessity is shown by the fact that, indeed, before the fall of the Ottoman Empire, whatever Kurdish dialect was written using the same sytem. This "traditional" Arabic-Persian writing system, close to Ottoman writing, was highly defective for vowels. Some of the texts considered for inclusion in the corpus present themselves in this notation, (to cite but some, [JABA, 1879], [NIKITINE], [BAYAZIDI-RUDENKO, 1963]8. Unfortunately, the specific problem of their electronic edition will not be touched here, as it is rather complicated, specially if contents must be accessible to readers of modern texts, and searchable through the same means.
2.1.1 Soranî
Called by the Kurdish linguists Southern Kurmandjî, spoken in the greatest part of Kurdistan of Iraq and Iran, this group of dialects is considered to be geographically "central", by opposition with "northern" and "southern". Because during Ottoman Empire, a secondary school (Rushdiye) was created in Sulaymania, the graduates from which could continue to study in Istanbul, the subdialect of Soranî spoken in Sulaymania could progressively replace Guranî as the literary vehicle (see section 2.2.5). MACKENZIE writes that the present Kurdish standard called Soranî is in fact a "idealized version of the Sulaymania dialect, which uses the phonemic system of the Piz_dar and Mukri¯ dialects" and indeed also some morphologic features which are not found in the Soranî spoken in Sulaymania.
Since the seventies, these dialects are routinely written in Iraq and Iran using a modified Arabic-Persian (hereafter A-P) alphabet proposed by Sa’îd Sidqî Kâbân as early as 1928 - quite the whole of Soranî texts candidates for corpus use this notation - but Western academic works are frequently transliterated or transcripted into Roman notations, as in [WAHBY, 1963], [MACKENZIE, 1961], [BLAU, 1978].
2.1.2 Kurmandjî
The dialects of this group, called by Kurdish linguists Northern Kurmandjî (by opposition to "Southern Kurnandjî" used for Soranî) are referred to as "northern". They are indeed spoken in the most northern parts of Kurdistan of Iraq and Iran, in the Kurdish areas of Syria, and in almost all of the Kurdistan of Turkey - in fact everywhere save where Dimîlî (Zaza) speakers live - and by the Kurds of ex-Soviet Union and Khorassan. Contrary to the central group, it has genders and cases, which does it a linguistically more archaic dialect than Soranî, with which it has phonological differences ("v" sound).
Those dialects are written according to the area :
- in Turkey9, in a Roman writing system often called Hawar from the newspaper in which it was first put forward in 1932 by Djeladet BEDIR KHAN, who also played a very important role in the process of defining a standardised northern Kurdish based on the written language used in this review by publishing its grammar [BEDIR KHAN and LESCOT, 1970]. A lot of the press and edition items interesting for Corpus collection use Hawar;
- in Iraq, where it is generically called Bahdînanî or Bahdînî, in the same A-P writing system which is used for Soranî ;
- in former USSR, in a modified Cyrillic alphabet which replaced since the forties the Roman writing in use since 1927, save in Armenia where Armenian alphabet had sometimes been used.
2.1.3 Dimîlî (Zaza)
Dimîlî, also called by Kurds Zazakî, is spoken in an area of Northern Kurdistan quite totally enclosed inside Kurmandjî area. If, linguistically, Dimîlî is not a Kurdish dialect but an Indo-Iranian language, culturally, there is little question that Dimîlî speakers in their majority feel Kurds. This is a strong argument for the inclusion of Dimîlî data into a Kurdish corpus, although (or perhaps better because) few data is actually published or gathered about it. Dimîlî is written using a Roman writing, inspired from the Hawar alphabet used in Kumandjî areas of Turkey.
2.1.4 Lorî
The situation of Lorî is quite different from the one of Dimîlî. As the latter, it is not a linguistically Kurdish dialect, being a Indo-Iranian language of the South-Western group (Kurdish in all its dialects is a language from the North-Western group). Anthropologically, the situation is rather complex, as it is difficult to ascertain which proportion of Lorî speakers feels or not Kurdish... This makes the question of including or not Lorî texts into the Corpus a still open one. It uses an A-P (Arabic-Persian) writing.
2.1.5 Guranî, the first litterary standard
If, linguistically, Guranî is not a Kurdish dialect but an Indo-Iranian language from the same group as Dimîlî, it is paradoxically the first literary standard for Kurdish writings, and beautiful Guranî poetry survives today, written in the "traditional" Kurdish writing already mentioned.
It is still spoken to date (even without taking its cousin Dimîlî in account) : in Iran, in Khanaqin area, and in Kermanshah area, which it shares with Lorî. In Iraq, in Hawraman (as Hawramî dialect), and it was also the language of the Kurds Faylî of Baghdad, now in their majority deported. In general, because of the policy to which they have been submitted since the seventies, Guranî speakers in Iraq tend more and more to assimilate to Soranî. Old Guranî uses the traditional Kurdish writing, modern dialects the actual A-P system.
2.2 Specific requirements for a Kurdish Corpus
The diversity of dialects, subdialects, and writing systems (synchronically and diachronically) makes more difficult the respect of the general principle outlined in section 1 : the respect of original data integrity during processing, and also brings to mind specific principles which should in my opinion be respected in the building of a Kurdish corpus.
A textual corpus is essentially aimed at being searched through by automatic means. This calls, at the level of internal storage, for a unique representation of all data - wherever it is coming from10.
On the other hand, what makes the interest of the computer tool for Kurdish, as mentionned in [GAUTIER, 1996], is precisely its ability to present data according to the user needs, giving for instance to a Kurd from Georgia the ability to browse Kurmancî texts or concordances in Cyrillic even if they were originally in Hawar or (in the case of Bahdinanî from Iraq) in A-P writing. This calls, at the level of user, for the a diversified présentation of output data.
At the beginning of the processing chain, if it is to be a cooperative initiative (and given the prospective funding, it will certainly be...), the contributor must be able to type, correct, control (in the case of an OCR) the data in reference to the originals, in the representation he masters. This calls for the ability to accept a diversified representation of input data, to be converted later if necessary, and by other persons, to the internal storage representation.
So the five following principles emerge from our analysis :
- Data must be entered into the corpus using a process and a presentation adapted to the specific configuration and skills of the person contributing to the corpus building ;
- Data must be the most possible internally represented in an unique way to allow for unified processing and research tools ;
- This unique representation must preserve the particularities the text manifested in its original presentation form ;
- The user must be able to request and obtain a data presentation according to his specific choices and needs ;
- This presentation operation must not alter the choices done during building, which are "cabled" into the corpus representation.
3. Representing and presenting Kurdish language data
We will now try to analyse if and how those principles may be concretely implemented. This will lead us to confront together dialects, writing systems, computer standards, and the organisation of such a project as a Kurdish language computer corpus. Looking at some of the real-life difficulties will sometimes lead us to come back to peculiarities of Kurdish writing systems which impact our ability to use such or such technical solution for presenting texts.
3.1 The representation of the Hawar system
There are several versions of the Hawar alphabet [ÇELIKER, 1996], one expressing the opposition short i / long i by the couple  /i , another notation using i/î. Although anyone knowing some Kurmandjî may determine in which of the two conventions any text is, reducing the notation to one of the two would be in contradiction with the 3rd principle, respecting the original conventions of the text.
/i , another notation using i/î. Although anyone knowing some Kurmandjî may determine in which of the two conventions any text is, reducing the notation to one of the two would be in contradiction with the 3rd principle, respecting the original conventions of the text.
From the input encoding point of view, ISO 8859-3, as well as PC codepage 1254, which are used to encode Turkish, allow for the choice, as they contains all the specific letters necessary to Kurdish ( , as well as î Î. Unfortunately, as the project supposes data exchange, the problem is not fully solved so : receiving on another type of computer a text file without full information about the encoding used to type it is quite useless. The only real solution to this difficulty is to follow the TEI guidelines and to ask contributors to use SGML entities for the non-ASCII characters (ie transforming any " î " into " î ") before transmitting or sending files11.
, as well as î Î. Unfortunately, as the project supposes data exchange, the problem is not fully solved so : receiving on another type of computer a text file without full information about the encoding used to type it is quite useless. The only real solution to this difficulty is to follow the TEI guidelines and to ask contributors to use SGML entities for the non-ASCII characters (ie transforming any " î " into " î ") before transmitting or sending files11.
If this proves impossible or difficult, a "better-than nothing" solution may be, without asking contributors to dig into the complexity of TEI headers, to ask them to include in the file a standardised header containing ordered samples as follows :
|
Please use now the font you use to type your contribution. then save the file AS TEXT.
Please type here a small c cedilla : >ç< ...
|
Even if SGML entities are used, the best is to obtain from the contributor a paper copy of any submitted text, as it will allow for the addition of structural tagging. Obviously, it will sometimes prove difficult, and in any case, getting at least the first few pages would be very welcome to ascertain the peculiarities of the encoding used.
Last point, it must be noted that the codepages mentioned (and indeed the Hawar it its actual form) do not allow for representation of some sounds specifics to Soranî, which has to be tackled for output.
3.2 The representation of Arabic-Persian writing
Knowing which encoding was used to enter a text is not a problem we will encounter for Hawar only. The entities solutions is a really practical one neither for Cyrillic nor for A-P writing, because it would imply a very large overload in file size. So the solution of a simplified file header could be a better-than-nothing substitute to it.
We will now try to tackle more precisely the problem of A-P writing system representation, which is - for specifically computer reasons - the most complicated we have.
3.2.1. The problem of Arabic standardisation
The first idea coming to mind concerning the Kurdish A-P writing system, is that it could just be adapted from the normal standard for Arabic. After all, this could be accomplished with adding only some specific characters and diacritics, and a lot of the writing signs used in Arabic proper are not used at all in Kurdish.
In fact, a lot of Kurdish fonts just use this approach. But the specific problem here is the lack of an universally used standard encoding for Arabic. There are indeed several official standards for Arabic : ISO 9036, a 7-bit code, coming from Arabic League ASMO 708, became the G1 ("upper-ASCII" slot), Arabic part of the 8-bit code ISO 8859-6, which groups together ASCII in G0 with Arabic in G1 (the two encodings became ISO standards at the same time, in 1987).
But as a matter of fact, ISO 8859-6 it is not used by Windows, Microsoft having developped its own codepage called CP 1256 ; and even the Mac encoding used for Arabic is not fully ISO conformant12. So type builders, when extending Arabic fonts to represent Kurdish, have had to work from different preexisting font encodings. As different producers have also made different choices concerning the codepoints of the Kurdish specific characters, we have now a total anarchy in Kurdish fonts encoding. So even reducing the Kurdish corpus to A-P would mean transcoding a lot of data...
3.2.2 UNICODE and ISO Extended Arabic
Transcoding to what ? UNICODE standard may seem a solution : indeed, thanks to the contribution of several US libraries which already tackled the problem of indexing Kurdish publications, it encompasses all the characters necessary for Kurdish. But it is not a real-life solution yet, as no software in general use allows using it : on PC, adds-on are necessary, on all platforms, few corpus tools are UNICODE-aware, and font-generating software makes difficult to generate UNICODE-encoded fonts.
With the recent publication of the ISO 11822 Extended Arabic standard [ISO 11822, 1996], conceived to be used in G1 position together with ISO 9036 in G0 position, an intermediate answer to the problem could have been found, while waiting the migration towards UNICODE. But although this standard seems at first sight to contain all the necessary characters to encode properly Kurdish ( ) it is in fact totally unusable as it lacks the character
) it is in fact totally unusable as it lacks the character  (UNICODE ARABIC LETTER AE, U+06D5), which it fails to distinguish from
(UNICODE ARABIC LETTER AE, U+06D5), which it fails to distinguish from  (UNICODE ARABIC LETTER HA, U+0647). This makes it a potential generator of mistakes, as contributors using it would have to use improperly one for the other to obtain a visual presentation corresponding to their needs13.
(UNICODE ARABIC LETTER HA, U+0647). This makes it a potential generator of mistakes, as contributors using it would have to use improperly one for the other to obtain a visual presentation corresponding to their needs13.
In fact, even if it is conceptually possible to encode Kurdish with the addition of this missing ARABIC LETTER AE character, the really correct solution would be to distinguish further, as UNICODE does, between three characters :
- ARABIC LETTER HA which is in ISO 9036 / ISO 8859-6 basic Arabic set, may adopt - as a final, the form
 (U+ 0647) - and which should not be used in Kurdish ;
(U+ 0647) - and which should not be used in Kurdish ;
- ARABIC LETTER KNOTTED HA (U+06BE) which always keeps the form ;
- ARABIC LETTER AE, a vowel which never takes the form .
But the ISO 11822 extended Arabic set contains neither ARABIC LETTER KNOTTED HA nor ARABIC LETTER AE.
4. A data entities and processing layered model
Lack of computer standards, profusion of dialects, subdialects, and writing systems, themselves in several flavours, shows that cooperatively building a Kurdish language corpus will be very complicated if not well thought in advance. To help rationalising to the best dealing with Kurdish language data, I will in the following discussion propose to define several hierarchised data layers, not unlike the "OSI-ISO model" for data teletransmission, which distinguishes seven layers, from physical (layer 1) to presentation (layer 7). I will also define some of the processing operations to be used on or between layers.
4.1 Layer 1 : Discourse
Language as it is spoken ; it may appear inside a corpus as a flux of sounds on a tape, on an audio CD, or as a digital file on a CD-ROM (or hard disk).
4.2 Layer 2 : Written transcription
Transcription is the first processing operation we encounter, which turns Layer 1 data into a written representation of the sounds of the language, also called a transcription, Layer 2 data.
As shows the use of a transcription system by [MACKENZIE, 1961 (1990)] in his famous studies about Kurdish dialects14, if the original data is Layer 1, it is quite possible to affect directly to a transcription system an encoding, that is a numeric representation of written data. The first such couple which comes to mind is International Phonetic Alphabet (IPA), for which UNICODE [UNICODE-1, pp. 36-37 and 129] provides a code page under the name "Standard Phonetic". This makes possible to get transcription files in a corpus without deciding formally of any writing system.
However, a system as IPA is much more precise than any writing system in common use15.. Reverting from Layer 3 written data - the vast majority of our data - to Layer 2 is quite impossible, as the contributor - even native speaker - may not have the necessary knowledge to do it, and furthermore scientifically irrelevant16. If the transcription files use a separate data representation, a word research across the corpus will not find its match in them, unless it is specifically programmed for it : if Layer 3 data is the basis of the whole corpus, transcription files should exist too in a Layer 3 version.
4.3 Layer 3 : Written language Input and Output presentation
This layer describes what is probably going to be, on the input side, the most part of the data susceptible of integration into the Kurdish corpus. The computer object which best fits this layer is the character font, as it allows to reproduce with fidelity the visual aspect of the data, which is most of the time what the contributor will be able to refer to for control.
Specially for A-P writing, a condition for this layer to be error-free is that input tools (fonts, keyboards drivers) must answer precise specifications which won’t allow to obtain a same presentation through different methods - hence with different internal representations.
A simple example is the use of an inaccurate (Arabic language, or ill-conceived Kurdish) font to generate the Soranî word herzan  (inexpensive). The problem is that it is possible to use two different ways of typing to obtain the same appearance, the correct one using the vowel ARABIC LETTER AE, the erroneous one a letter ARABIC LETTER HA in its final form followed by a space which forbids its changing into
(inexpensive). The problem is that it is possible to use two different ways of typing to obtain the same appearance, the correct one using the vowel ARABIC LETTER AE, the erroneous one a letter ARABIC LETTER HA in its final form followed by a space which forbids its changing into  17. The font used in this paper does not allow for this common mistake, as the final form of the HA letter as been modified on purpose : an user trying the "bad" way will only obtain
17. The font used in this paper does not allow for this common mistake, as the final form of the HA letter as been modified on purpose : an user trying the "bad" way will only obtain  18.
18.
I will subsume the written language output presentation under the same layer as input, just distinguishing it by the name of 3'. To respect the principle that the user may obtain the representation he wants, have to be built what the user will see as transliteration functions, as they realise a transformation, a mapping from one writing system onto one other (as from Arabic-style to Cyrillic-style)19. In fact, if an internal encoding is used (see section 6), there won’t be formally real transliteration functions between writing systems in the corpus : output form is then generated from the internal encoding, itself generated from the input form, and there is in no way direct transliteration from any written form to any other (see figure below).
Output generation from a common encoding vs direct transliteration
Note there is input transcoding, but output generation (see section 4.6.1)
4.4 Layer 4 : Graphic realisation
This level is concerned with the differents conventions which may exist inside a given writing system, as the already mentionned choices in Hawar between the opposition /i and i/î. Another example in A-P writing is its notation for long vowels  and
and  , which underwent an evolution during the last thirty years. First written
, which underwent an evolution during the last thirty years. First written  and
and  , they were later noted
, they were later noted  and .
and .
Another example is the vibrant ra  . Depending on texts, the diacritic may be also written over the letter, and as the ra is always vibrant at initial position , then not written at all there...
. Depending on texts, the diacritic may be also written over the letter, and as the ra is always vibrant at initial position , then not written at all there...
Those choices must be kept in the internal encoding of the corpus as they existed in the original text, but they may also be of concern at output time, as the user must be able to override them for his convenience. Furthermore, as already mentionned, the existence of different writing conventions must not impact the results of research functions.
A solution is to precise the graphic realisations settings valid for a text in the header of the file, which will allow simultaneously efficient, unified research, and proper rendering when needed. This would for instance apply as well for Hawar alternate / i / î conventions 20.
4.5 Layer 5 : Orthography
Orthography is the way of writing a language in its own writing system. For instance, in Hawar, the long i is often changed into a short one before a y (televîsiyon and not televîsîyon). Another case is the writing of the complex verbs. When they are nominalised, which is very often in Kurdish, their parts are written together, but not when they really function as verbs... As Kurdish orthography may change according to publication or author, those characteristics are an information which must be kept through processing. There are differents orthographies as well in A-P system. Fortunately, those peculiarities concern us here only as they are a characteristic of the data, chosen by its writers, and which must not be lost21.
4.6 Layer 6 : Written language internal representation
From Layer 3, which allows for several presentations corresponding to different writing systems, data will have to be submitted to a transcoding to be converted to the unique internal encoding which I took as hypothesis. I will define transcoding as a transformation from one encoding to another, which bears in itself no relationship with the writing system of the text submitted to the processing. This is the same operation which will be accomplished to obtain an output presentation form according to the needs of the user. This section will try to analyse the relationships between input, internal, and external forms.
4.6.1 A proprietary multi-writing systems encoding
The principle of a unique encoding, independant of the original writing system of the data, means that it is not possible to use UNICODE. Indeed it separates very clearly characters other standards fail to distinguish (see sections 3.3.2 and 4.3), but the problem is that each UNICODE codepoint is linked to a character inside a specific writing system. In short,  is not
is not  is not
is not  ... So the answer appears to be a proprietary encoding, a feature which the TEI Guidelines allow, by distinguishing internal data storage from data exchange needs.
... So the answer appears to be a proprietary encoding, a feature which the TEI Guidelines allow, by distinguishing internal data storage from data exchange needs.
We already saw that a phonetic transcription, whose level of precision is too high for our data, was not possible to use either. What is needed is an intermediate way of recognising sequences of characters possibly linked to several parallel and corresponding representations of Kurdish : a common internal representation meaning at the same time  ,
,  and kirdin, the choice between those being done only at output time. In this conception, the internal form is not linked to a writing system, so an output may be considered as an actualisation of one of the possible significations of the internal encoding. This is essentially different of a system of direct transliteration between those three systems (see figure preceding page).
and kirdin, the choice between those being done only at output time. In this conception, the internal form is not linked to a writing system, so an output may be considered as an actualisation of one of the possible significations of the internal encoding. This is essentially different of a system of direct transliteration between those three systems (see figure preceding page).
If it is to be always possible to generate any of the three presentations from the internal representation, that is, to make output generation possible, the level of precision of this proprietary encoding must be the one actually achieved by the most precise of the three systems in any case.
In fact, the physical encoding chosen (the real codepoints) is not so important once the those principles have been agreed upon. Together with the internal representation, the contextual information added to the file will keep track of the original writing system and allow to transcode to UNICODE in an unambiguous way as well as to any standard or specific font or system codepage, which will make the system TEI-conformant.
4.6.2 Font-level transliteration between Kurdish writing systems
A very interesting example of output generation from a common encoding using the "best precision" principle is the LaserKURDISH® set of fonts 22. Below is an example of its use, as this sentence was typed only once before having its font changed :

- Note: At least it is so in the original (non-HTML) version of this paper, typed on a Macintosh. As this HTML version has been prepared on a PC, which does not have yet this set of fonts, the output has been simulated. The Soranî part makes use of the excellent Naskh set of Kurdish fonts produced by Decotype)
|
On the output side, LaserKURDISH effectively works as the generation system I propose, and certainly shows the direction we must go as far as internal encoding is concerned. But on the input side, from which it may be seen as a font-level transliteration system, it bumps into the following problem : each of the three Kurdish writing systems has areas less precise than the two others.
So obtaining text simultaneously correct for each of them requires inserting invisible characters (for instance in A-P to represent the unwritten short i which will become Cyrillic  ; in Roman or Cyrillic for the A-P initial vowel compound componant
; in Roman or Cyrillic for the A-P initial vowel compound componant  using codes corresponding to two characters (as , which is transliterated into cyrillic y and Hawar û)23... So while LaserKURDISH™, which is conceived to be a marvelous linguist's tool, succeeds at it, it would certainly prove difficult to ask contributors to use it as input tool. It would also make difficult to use already typed texts.
using codes corresponding to two characters (as , which is transliterated into cyrillic y and Hawar û)23... So while LaserKURDISH™, which is conceived to be a marvelous linguist's tool, succeeds at it, it would certainly prove difficult to ask contributors to use it as input tool. It would also make difficult to use already typed texts.
4.6.3 Algorithmic transcoding between input and internal forms
It seems to me that it should be the work of the functions doing the transcoding from Level 3 (Input) to Level 6 (internal) data, together with the input tools already mentionned section 4.3 (fonts, keyboard drivers), to relieve the contributors of the typing problems we just mentionned.
I think that where the character-to-character approach fails, an algorithmic transcoding may solve a lot, and that it is the direction in which we should search. In the place which remains, I will give one example from what I experimented using two open and parametrable softwares, UPenn Transcribe on Macintosh and BitTrans on PC24. Briefly, the two softwares I used worked as formal grammars, and I will use this formalism to explain my example.
The initial vowels in A-P form compounds with the letter : so the word azadî (liberty) is written 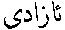 and not
and not 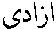 .
.
The transformation of this case from Hawar to A-P in UPenn Transcribe is as follows :
- define a character-to-character application a as :
a(a, b, c, d, e, f...) = ( ,
,  ,
,  ,
, 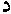 , ,
, ,  ...)
...)
- define a class of vowels V = {a, e, î, i, o, u, û}
- define a class of "spacing characters" S = {<space>, <comma>, ...}
- define the transformation rule : SV
 a(S) a (V).
a(S) a (V).
In the opposite direction, A-P to Hawar, I was able to build a rather complete transcoding function using the PASCAL-like language of the Fourth Dimension® DBMS [GAUTIER, 1996]. Note that the system may precisely use the presence of to recognise if is to be represented as u or w in Hawar. Some decisions, notably to decide where inserting the short i in Hawar, ( must be rendered as kirdin / and not kridin /  ) require morphologic knowledge, so the accuracy is not 100 %.
) require morphologic knowledge, so the accuracy is not 100 %.
As a last practical remark, I would want to draw attention to the fact that, as a lot of SGML-aware corpus tagging software is not yet able to process correctly Arabic-style text, the use of a Romanised version could, for the time being, be the first way of working with it25...
5. Conclusion
Research must continue as to the best ways to represent Kurdish in its diversity and richness. I hope that the distinctions I tried here to draw between different layers of data and processing functions will prove useful to conceive a system allowing collaboration to build the first Kurdish language Corpus.
This is indeed only preparatory work. Areas to look to in priority seem to me adapted input tools, and the problems of intelligent transcoding. From there, if a corpus may be created, it will have a very important impact on lexicographic - and on linguistic research on Kurdish in general, and other areas as Kurdish NLP will for the first time in the history of this language be at hand. This could have a cumulative effect on the research, and very practical applications as text correcting and semi-automatic multiscript conversion for edition. This could prove very important for this people separated - among other things - by the writing systems it uses.
Footnotes
- After studies in Kurdish (Institute of Oriental Studies, Paris), computer science (master, 1988) and anthropology (Ph.D, 1994), G. GAUTIER studied mandarine Chinese in Taiwan while working as technical writer and assistant professor of French language and literature. He now works in Paris as a professional trainer and consultant for multilingual computer science and multicultural education. Secretary of the Centre for Kurdish Studies, an association, he is researching there on a proposal for a Kurdish language Corpus.
- This is shown in part by some of the remarkable researches published in [MORACCHINI, 1996], specially concerning Corsica.
- Those proposals are detailed inside [URL: GAUTIER & METHY] (Preliminary reflexions for the constitution of a national corpus of Kurdish language, GAUTIER & METHY, Centre for Kurdish Studies), broadcast through the Internet.
- This also includes Kurdish translations of foreign texts, for alignments and lexicographic purposes.
- A great amount of raw text allows for instance to study words and phrases frequencies in the language and collocations, or even to build concordances. Concordances may be obtained through an automatic search across the whole corpus for all the occurences of a given word. If it is a synchronic corpus, they are of obvious interest to the lexicographer, but even in a diachronic corpus, which potentially presents an history of the studied language (for instance from XVIIth century to now), a set of dated concordances may well allow the historian of ideas to trace the appearing and rise of a concept or of a new meaning (a common example of this being a study using the ARTFL corpus, which unveiled the interesting fact that the use of the word "revolution" in its meaning of "political upheaval" increased significantly in the french texts during the years preceding French Revolution). For Kurdish, such a contribution to the history of ideas would be indeed interesting.
- Obviously, the researcher also has to decide which information is best adapted to the aims of the corpus. This problem is out of the scope of this paper, and is considered in the Preliminary reflexions for the constitution of a national corpus of Kurdish language, already mentionned.
- I am grateful to Sergi BASSOLS y CODINA, who proofread this part of the present paper with his linguistic competence. Any remaining mistake is my own.
- A detailed discussion of the different writing systems used for Kurdish or of the subdialects of each group of dialects would be out of the scope of this paper. Furthermore, I lack the linguistic competence to discuss subdialectal problems, and those are still themselves subjects of research. Some peculiarities in dialects or writing will be dwelled into in further sections, only as they impact directly the problem of data representation in a corpus. Suffice it to say that, only for Iraq, MACKENZIE [MACKENZIE, 1961 (1990)], in one of the only subdialectal studies to date on Kurdish, distinguishes in the Sorani group eight subdialects : Suleimaniye, W
 rmwa, Bingird, Pi
rmwa, Bingird, Pi dar¯, Arbil, Rewandiz, X
dar¯, Arbil, Rewandiz, X
 nw and Mukri, this last one being the only one to be a dialect spoken in Iran, and in the Kurmancî group seven : S
nw and Mukri, this last one being the only one to be a dialect spoken in Iran, and in the Kurmancî group seven : S rc
rc , Akre, Amadiye, Barwr-or, Gull, Zakho and Sheikhan... Logic dictates that these numbers could easily be doubled if we consider other Kurdish areas as well. The dialectal characteristics of any Kurdish corpus data, when they are available, should be obviously part of the contextual information already mentionned.
, Akre, Amadiye, Barwr-or, Gull, Zakho and Sheikhan... Logic dictates that these numbers could easily be doubled if we consider other Kurdish areas as well. The dialectal characteristics of any Kurdish corpus data, when they are available, should be obviously part of the contextual information already mentionned.
- As much as it is possible according to the law to publish Kurdish texts in Turkey... In fact, the vast majoritiy of publications is done in exile.
- The other way would be to build sophisticated research functions able to take different encodings in account. In fact, the real-life solution could well be a combination of the two approaches...
- In the case of a transmission through Internet , using entities is a much better solution than resorting to another transcoding (UUencoding or MIME), which ensure the transmission without modification, but do not allow to ascertain the original encoding.
- Although it may be argued that the difference is minor, being limited to the right-to-left space (RTLSP), and some extended characters placed into unattributed codepoints.
- Fortunately, it seems that ISO 10754 Extention of Cyrillic Alphabet [ISO 10754, 1996], published at quite the same time, and which appears as an extention to be used in the G1 position with the cyrillic G1 part of ISO 8859-5 in G0 position, is exempt from any such defect, presenting all the necessary Kurdish letters, including the CYRILLIC SMALL LETTER SCHWA (codepoint 6D / 7D in capital). Conversely, note UNICODE does not allow for a CYRILLIC SCHWA, probably because there is already a LATIN SMALL/CAPITAL LETTER SCHWA (U+0259 / U+018F).
- It may be noted that the transcription often separates words, which strictly is not an obligation at all for representing sounds. The way in which words are separated may be seen as an influence of level 3.
- Note that we may be in part happy of it, because if the commonly used writing system represented every inter-speaker, inter-dialectal, inter-subdialectal variations, reading the written records of any language could become impossible ! For instance, the Hawar Roman notation is in fact a good compromise between several dialectal realisations...
- [RIZGAR, 1993] for instance, mentions that he was not always able to decide if a consonant in a word was or not accented, as he never heard it pronounced. And it may be indeed better, as even if the typer knows how a given word should be pronounced according to his idiolect or some sort of standard way, the profusion of subdialects makes this information non relevant as linguistic data concerning a text produced by someone else.
- The reader will remember that it was precisely the lack of ARABIC LETTER AE in ISO Extended Arabic which made us concluding it was not really usable.
- Another example of a ill-conceived font I met is the erroneous possibility to generate the hewt diacritic either as one separate codepoint, or together with the letter it concerns... Note that UNICODE allows several ways to generate é.
- So transliteration appears as a transformation of signs between two writing systems, theoretically linked in no way with the actual phonetic realisation of a sign in any of the two systems considered. It is hence very different of transcription, with which it should not be confused.
- For quotation purposes, it should be possible to override these settings at word level, without impacting their encoding. For instance a Kurdish version of this paper would need to use the two writing conventions simultaneously...
- Sometimes, the orthographic variation may be linked to differencies in phonological realisation (sub-dialects), as when the Kurmandjî verb ajotin (Diyarbekir) is found written as hajotin (Mardin), or when post-positions re, de, are realised as ra, da. Obviously those characteristics do not concern us here, as does not the problem of linguistic and semantic variations. One example : the name of a piece of clothing changes from a valley to another at the same time as its shape continuously and its function evolve... [MOHSENI, personal communication].
- I am very grateful to Michael CHYET for having drawn my attention to this set of fonts, to the conception of which he contributed. LaserKURDISH is distributed by and a registered Trademark of Linguist's Software, which maintains a Web site at http://www.linguistsoftware.com/.
- Other examples of the difficulty of this correspondance are that Cyrillic is more precise than Hawar in distinguishing aspirated consonants through a diacritic (posterior quote) where Hawar does not [RIZGAR, 1993], Arabic-Persian is more precise than Hawar in separating
 and
and  where Hawar uses the x for the two...
where Hawar uses the x for the two...
- I am convinced other researchers would be able to to experiment further in this direction using PERL scripts, the freeware BBEdit on Macintosh, or even the grep Unix command, and I hope some will.
- Author-Editor™ 3.1 does not make easy - even on a Macintosh - to work with Arabic-Persian text., as it does not manage correctly the position of the cursor. But as it allows to change fonts, it allows to tag a text typed in LaserKURDISH Roman font, and then turn it to its Arabic-Persian visual aspect... (Author-Editor is a TradeMark of SoftQuad).
BIBLIOGRAPHY
[BAYAZIDI-RUDENKO, 1963] - BAYAZIDI, Mela Mahmud, ‘Adat u rasumatname-ye Akra¯diye, ("Habits and customs of Kurds"), original manuscript (Kurmandjî in Ottoman characters), pub. by M. B. Rudenko, Moscou, 1963, introduction and Russian translation : Pravy i Obyc’aj Kurdov.
[BEDIR KHAN and LESCOT, 1970] - BEDIR KHAN, Djeladet et LESCOT, Roger, Grammaire Kurde (Dialecte Kurmandji), Librairie d’Amérique et d’Orient, Paris, 1970.
[BERNARD, 1988] - BERNARD, H. Russell, Research methods in cultural anthropology, SAGE, 1988.
[BLAU, 1978] - BLAU, Joyce, Manuel de Kurde, Paris, Klincksieck, 1978.
[ÇELIKER, 1996] - ÇELIKER, C., Çend Pirsên Alfabeya Kurdi, We anên Roja Nû, Stockholm, 1996.
anên Roja Nû, Stockholm, 1996.
[GAUTIER, 1996] - "Dirêjî Kurdî : a lexicographic environment for Kurdish language using 4th Dimension", in ICEMCO 1996 Proceedings, 5th International Conference and Exhibition on Multilingual Computing, University of Cambridge, 11-13 april 1996.
[HABERT et al., 1997] - HABERT Benoît, et al., Les linguistiques de corpus, Paris, Colin, 1997
[ISO 10754, 1996] - International Standard, Information and Documentation - Extension of the Cyrillic alphabet coded character set for non-Slavic languages for bibliographic information interchange, ISO, 1996.
[ISO 11822, 1996] - International Standard, Information and Documentation - Extension of the Arabic alphabet coded character set for bibliographic information interchange, ISO, 1996.
[JABA, 1879 (1973)] - JABA, Auguste, Dictionnaire Curde-Français (Kurdish-french Dictionary), published by Ferdinand Justi, Imperial Science Academy, Saint-Pétersbourg, 1879, reed. Biblio Verlag, Osnabrück, 1979
[MACKENZIE, 1961 (1990)] - MACKENZIE, D. N., Kurdish Dialect Studies, School of Oriental and African Studies, London Oriental Studies, vol. 9 & 10, S.O.A.S., 1961 (1990) & 1962 (1990).
[MORACCHINI, 1996] - MORACCHINI, Georges, ed., Bases de données linguistiques : Conceptions, realisations, exploitations, Actes du Colloque International de Corte (11-14 octobre 1995),Unov. de Corse - univ. de Nice Sophia Antipolis, 1996.
[MOHSENI, to be published] - MOHSENI, C., Ph.D. about Kurdish clothing and cultural identity.
[NIKITINE] - NIKITINE, Basile, Etudes sur les Kurdes (Studies on Kurds), Etudes rassemblées par Halkawt HAKIM, including Kurdish texts published in several reviews in 1923, 1926 and 1933, INALCO, Paris, 1982.
[RIZGAR, 1993] - RIZGAR, Baram, Kurdish-English English-Kurdish Dictionary, London, 1993.
[SINCLAIR, 1996] - SINCLAIR, J., Preliminary Recommendations on Corpus Typology, Technical Report, EAGLES (Expert Advisory Group on Language Engineering Standards), may 1996, CEE.
[Text Encoding Initiative, 1996] - Text Encoding Initiative, TEI P3, Guidelines for Electronic Text Encoding and Interchange, C. M. Sperberg-McQueen, Lou Burnard, eds., Chicago, Oxford, 1996.
[UNICODE-1, 1991] - The Unicode Consortium, The Unicode Standard, Worldwide Character Encoding, version 1,0, vol. 1, , Addison-Wesley, 1991. See also Unicode Standard version 2.0 and 2.1
[URL : BALL, 1997] - BALL, Cathy, Concordances and Corpora, Personal www page of Cathy BALL, http://www.georgetown.edu/cball/ e-mail : cball@guvax.georgetown.edu, 1997.
[URL : Corpus Encoding Standard, 1997] - Corpus Encoding Standard <http://www.cs.vassar.edu/CES/>, 1997
[WAHBY, 1963] - WAHBY, T., and EDMONDS, C. J., A Kurdish-English dictionary, Oxford Univ. Press, 1966.

CEK Home Page
